No Coding Required: Train Your Own AI Model
This blog post is for the dreamers. If you are an AI expert you won’t learn a thing. But if you have never interacted with a machine learning model — this is for you.
Hugging Face is cool.
Like… really cool.
(Yes. I know nobody uses ‘cool’ anymore except me.)
Anyway. The reason I’m excited is this:
In just a few hours I trained my own AI model and used it to generate images in my own style.
And I did it all without writing a single line of code or installing complex packages on my computer. I did it all using open source tools and models. And I did it without knowing much about modern machine learning.1
Cool, right?
In one morning in learned about DreamBooth, found implementations of the method based on Stable Diffusion, discovered Hugging Face Spaces, and combined all of this to train my own text-to-image model.
If you don’t know what any of this means, don’t worry. I’ll give you the high level introduction you need in just a moment. If you are curious, excited, and ready to learn that’s all I need.
Power to create
The first model I trained isn’t worth much. But the experience of training my own model was exhilarating. I suggest you give it a go to experience what it feels like. Even if you do not have a productive use case right away, you’ll learn something in the process.
I learned to code many years ago. So I can’t remember what it felt like. But I imagine it felt similar to this. As I type in prompts and watch the computer return never-seen-before images it feels like I have unlocked a powerful creative force. By typing on my keyboard I now have the power to shape elements. Using just my brain an a few keystrokes I can build new things. The virtual world is suddenly wide open and only my imagination is the limit.
This power to create is just wonderful. I’ve enjoyed it immensely over the years with programming. And I’m excited for a new chapter on the journey. If AI models continue to be open and accessible we are in for a ride.
Results
Here are some images generated using my very own curious-builders-style-v1 model:

Big mountains in sks style

Round earth seen far away from space station in sks style

Eiffel tower in sks style

A planet in space in sks style
Not that impressive, I know. Especially not compared to Midjourney showcases or PromptHero featured images. (Take a moment to browse through the showcases if you have’t already. The results are wild.)
But still. This is my fist attempt. I made lots of mistakes.
Two things to note:
- You may have noticed all the prompts are in “sks style”.
sksis the unique identifier I trained the model to recognize. More on that in a moment. - The model is clearly overfitted. The prompt “a planet in space in sks style” has an astronaut writing on a laptop. Not what I asked for. Take a look at the images I used to train the model on and see if you can spot my mistake.2
The learning method
Let’s get to it. How did I train a text-to-image model to use my style when generating images?
The method I used is called DreamBooth. The website for the paper does a good job explaining the method and showing some results. The tl;dr:
In this work, we present a new approach for “personalization” of text-to-image diffusion models (specializing them to users’ needs). Given as input just a few images of a subject, we fine-tune a pretrained text-to-image model (Imagen, although our method is not limited to a specific model) such that it learns to bind a unique identifier with that specific subject. Once the subject is embedded in the output domain of the model, the unique identifier can then be used to synthesize fully-novel photorealistic images of the subject contextualized in different scenes.
Meaning: I can provide DreamBooth a few images of e.g., myself (subject) along with my name (unique identifier). I then ask DreamBooth to train using these images. Once trained I can prompt the model to generate images using my identifier. E.g., I can ask the model to generate an image of me posing next to the Eiffel Tower.
DreamBooth can be used to personalize images with a subject. But it can also be used to personalize images with a style — which is what I attempted in my experiment.
That’s DreamBooth. Next up on our agenda is Stable Diffusion.
All you need to know here is that DreamBooth is a method for personalizing text-to-image diffusion models. It is not a text-to-image model in itself. So we need one of those. And the most popular public one right now is Stable Diffusion.
How to train
The DreamBooth paper did not include a demonstration. Only images. But a number of implementations have popped up. Here are a few I found:
- XavierXiao/Dreambooth-Stable-Diffusion
- JoePenna/Dreambooth-Stable-Diffusion (designed for digital artists)
- replicate/dreambooth (run in cloud. Or locally.)
- TheLastBen/fast-stable-diffusion (a colab notebook)
- Hugging Face Colab (another colab notebook. Learn step-by-step)
- Dreambooth Training UI (Hugging Face Space)
The complexity of using these implementations range from easy (click a few buttons) to setting an environment and running python code on your own device.
For my first attempt at this I went with the easiest of the easy implementations: the Hugging Face Dreambooth Training UI space. It hides a lot of configuration options which makes it a good place to get started. And if you want more details you can see (and fork) all of the implementation details.
The training UI has enough guidance that you should be able to just follow that. In any case, here is what I did:
- Duplicated the space. (gives you a personal copy you can change and modify)
- Upgraded my hardware to T4 small3
- Selected the
styletraining option - Chose v1-5 base model
- Added a few images
- Used
sksas my made up concept prompt - Named my model
curious-builders-style-v1 - Added a write access token
- Trained the model
My first run failed. I don’t remember what happened. The second run succeed and poof: suddenly I had a model attached to my Hugging Face account. A model called curious-builders-style-v1. If you go to that link you can see some of the model details — what images and base model I used to train. You can even test the model using your own prompts (although it is very slow and often fails).
Using the model
I now have a text-to-image model. With a few lines of code I can use it with the Hugging Face diffusers library:
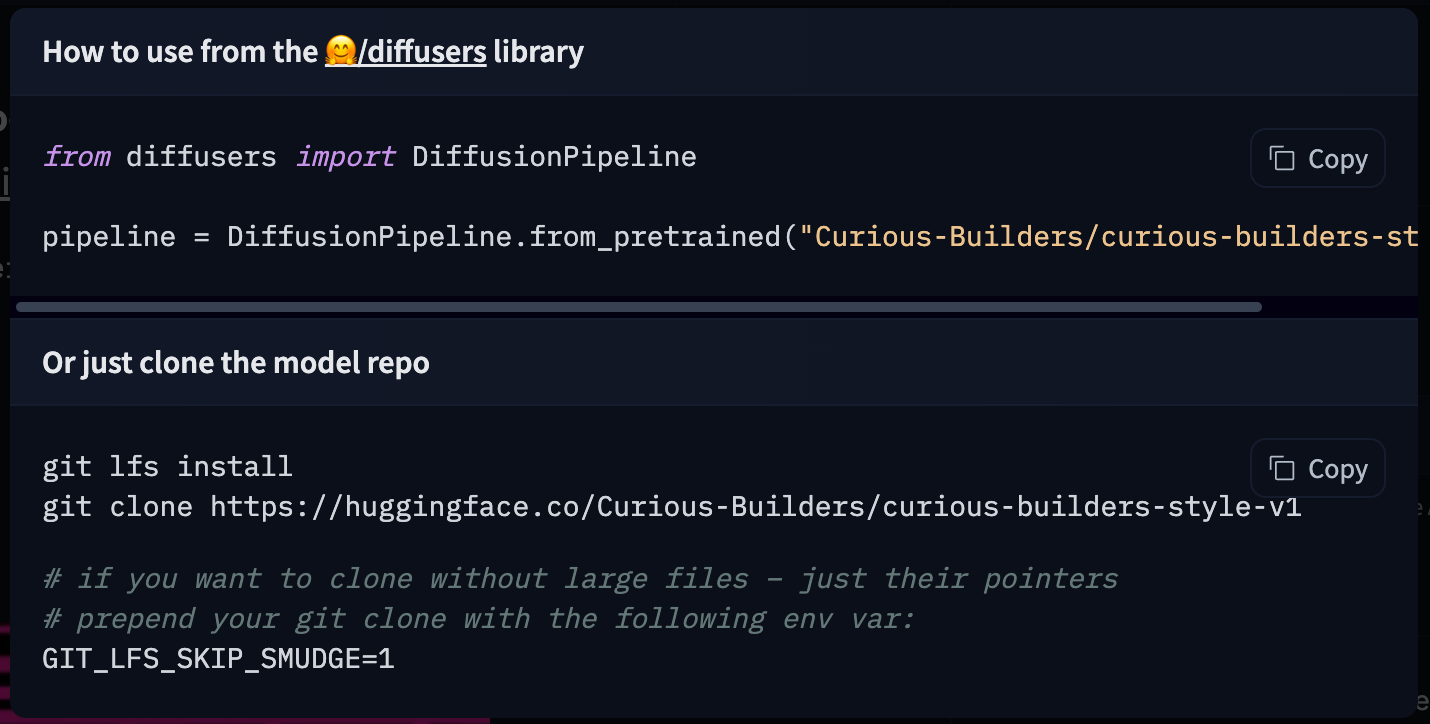
Or a few clicks I can deploy it to a Space:
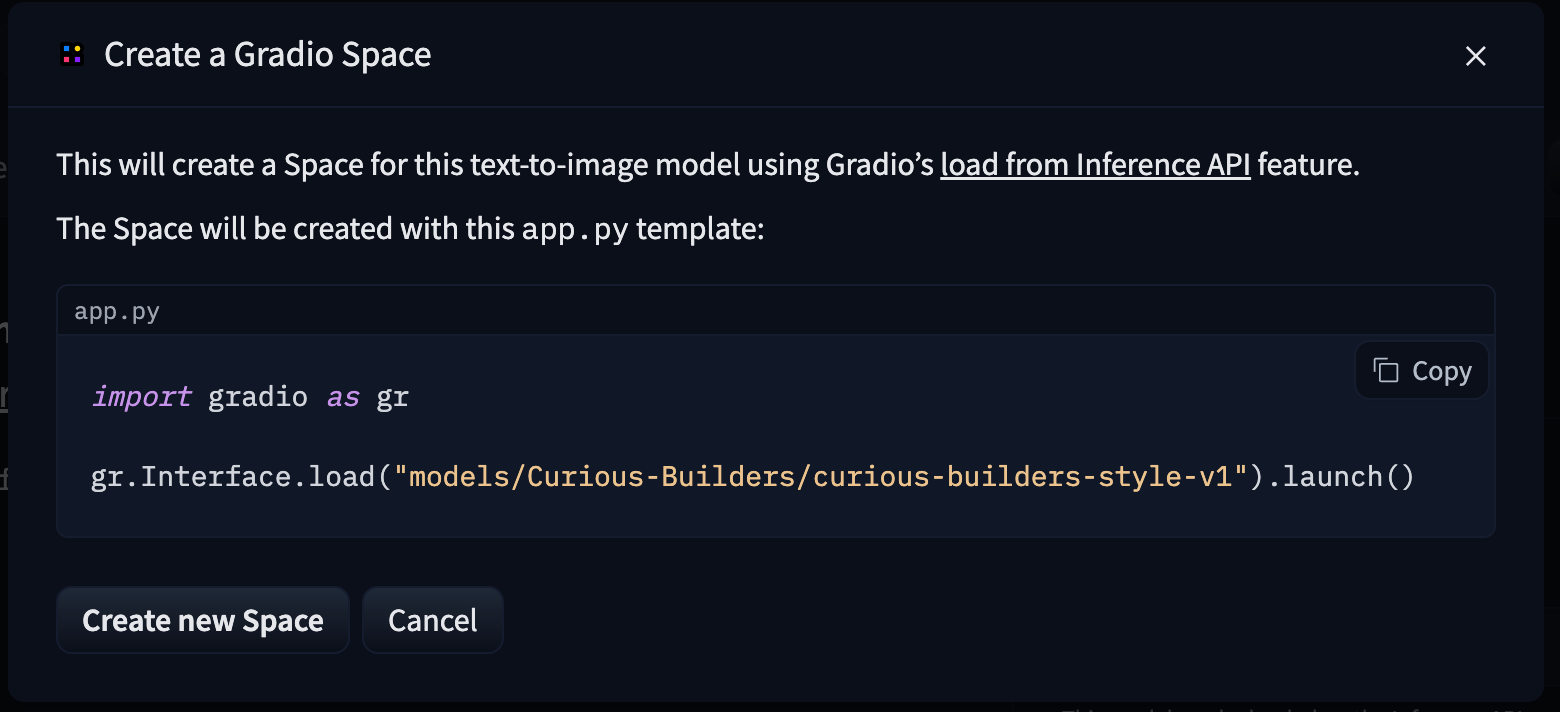
My creativity and imagination is the limit now. I have the power to train and use my own text-to-image models. What will I create?
Hugging Face
The motivation behind is blog post is twofold:
- I wanted to share my experience training a ML/AI model
- I want to promote Hugging Face
I don’t know the team behind Hugging Face and they don’t know me. But I found the website as I started digging into machine learning and so far I have been blown away.
You don’t have to be an expert to use — or even train — machine learning models. Thanks to tools and platforms like Hugging Face and Google Colab you can start experimenting right now.
Go visit some of the community spaces — but be careful as this can quickly become a time sink. Or maybe try some of the start of the art models and see where the field is at. You can also browse the list of tasks machine learning models are starting to solve — what creative use cases can you come up with using these?
The frontier is wide open for you to explore.
If you want more DreamBooth, here’s some inspiration:
- Analog Diffusion (space)
- GTA5 Artwork Diffusion (space)
- Openjourney (space)
- Classic Animation Diffusion (+ many others from nitrosocke)
- Van Gogh Diffusion
Footnotes
-
I have studied computer science, including a course on machine learning. So I have a solid foundation. But I have not actively followed the advances in machine learning for years. And I believe you will be able get the same results as I have in this blog even if do not have the same background knowledge as I do. ↩
-
All the training images are of the same subject: an astronaut writing on a laptop. I wanted the model to learn about the style of these images. But as all the images contain the same subject it has associated that subject with the style too. Beginner mistake. For better results I should have picked a more diverse set of images. ↩
-
My first training run failed so in total I ran the T4 for 1 hour 28 minutes and paid $0.88. ↩